K-Means 硬聚类算法
 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
计算步骤:
- 从N个文档随机选取K个文档作为质心
- 对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类
- 新计算已经得到的各个类的质心
- 迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束
决定最优值
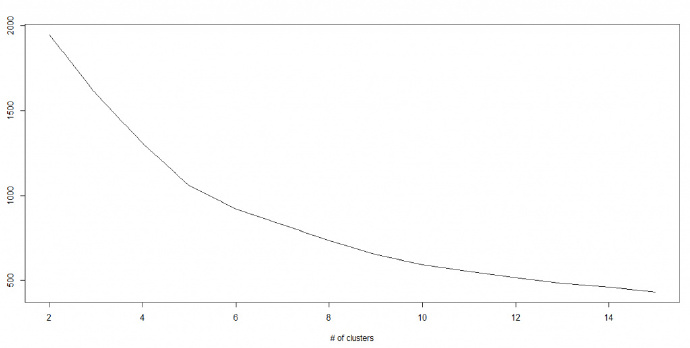
K – 均值算法涉及到集群,每个集群有自己的质心。一个集群内的质心和各数据点之间距离的平方和形成了这个集群的平方值之和。同时,当所有集群的平方值之和加起来的时候,就组成了集群方案的平方值之和。
我们知道,当集群的数量增加时,K值会持续下降。但是,如果你将结果用图表来表示,你会看到距离的平方总和快速减少。到某个值 k 之后,减少的速度就大大 下降了。在此,我们可以找到集群数量的最优值。
Programing
Sklearn
#Import Library
from sklearn.cluster import KMeans
#Assumed you have, X (attributes) for training data set and x_test(attributes) of test_dataset
# Create KNeighbors classifier object model
k_means = KMeans(n_clusters=3, random_state=0)
# Train the model using the training sets and check score
model.fit(X)
#Predict Output
predicted= model.predict(x_test